前言
一、什么是编译器前端
让机器理解代码并生成可执行文件,这是一件很困难的事情,所以编译器是一个非常浩大的工程,它内部工作过程十分复杂。
不过计算机科学中有句名言,任何一个问题都可以通过增加一个中间层/抽象层来解决,这也是最常用的计算机分层思想。
All problems in computer science can be solved by another level of indirection. —— David John Wheeler
所以为了降低编译器工程的复杂性,提高发展效率,一般把编译器分为两个完全解耦的两个部分
- 编译器前端 :只负责理解代码,不考虑各种CPU指令不兼容等问题
- 编译器后端 :只负责生成可执行文件,不考虑各种语言特性
为了让两个部分可以连接在一起工作,所以必然存在一个部分的输出是另一部分的输入,很明显,编译器前端的输出,就是编译器后端的输入。
这样,两个部分只需要约定好数据格式,就可以大幅度提高编译器的发展效率,编译器整个工作流程也变得非常简单清晰了,如下图所示,如果对图中的编译器前端不理解没关系,接下来的 第二节《编译器前端的原理》 会对这部分进行讲解
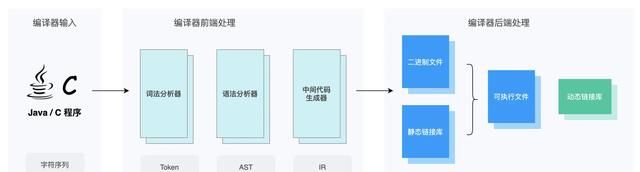
结论 :所以编译器前端就是编译器中的前端部分,负责理解代码并生成中间语言
二、编译器前端的原理
既然编译器前端的工作是理解代码,那么它的原理是什么呢,首先看下面一段简单的C语言代码
int age = 18;复制代码从人类阅读代码的角度来看,我们是如何理解上述代码的呢
1、局部理解
- 看到 int 关键字
- 看到 age 标识符
- 看到 = 赋值符号
- 看到 18 字面量数值
- 看到 ; 结束符
局部理解的过程,就是词法分析的过程
2、全局理解
通过联系孤立的、局部的理解结果,可得到一个整体 int age = 18 ;,对其在脑海中进行全局理解后,发现它符合C语言的整型赋值语法
整型赋值语法 -> 关键字 标识符 赋值符号 字面量关键字 -> int | long标识符 -> [a-zA-Z_]+[a-zA-Z+_*0-9]*字面量 ->[0-9]+复制代码所以通过全局理解,最终可知道上面代码是一个整型的赋值语句
全局理解的过程,就是语法分析的过程
3、总结
结合人类理解代码的过程,编译器前端主要可以分为局部理解和全局理解两个步骤,其中
- 局部理解会生成一个一个的理解结果,称为Token
- 全局理解会把孤立的token联系成为一个整体,进行语法规则匹配,如果符合语法则理解成功,否则理解失败
三、词法分析器的介绍
词法分析器就是在做对字符序列的局部理解,每完成一次局部理解,就生成一个Token。常见的Token包括操作符、符号、空白符、关键字、标识符、数字、浮点数、字符串、字符等。
所以词法分析器的工作内容也比较简单,只要能把输入的字符序列,生成一个有序的token列表即可。
四、词法分析器的原理
1、直接扫描法
直接扫描法的思路类似二重循环的暴力法,每一轮的扫描都是如下过程
- 先第一层的扫描,根据第一个字符判断属于哪种类型的token
- 进入第二层的扫描,向后依次读取,直到读出一个完整的token为止,跳出第二层循环
- 继续开始第一层的扫描
(1) 伪代码
let end = s.length-1;for(let i=0; i<=end; i=n){ let tokenType = justTokenType(s[i]); switch(tokenType){ case "string": let queue = []; for(let j = i; j<=end-1; ++j){ if(!match){ break; } queue.push(s[j]); } let token = queue.join(''); tokens.push(token); n=j+1; break; }}复制代码(2) 缺点
- 逻辑非常复杂
- 可能存在回溯情况,可能需要记忆已匹配的前N个字符,效率低
- 大量IF判断,可维护性差,扩展性差
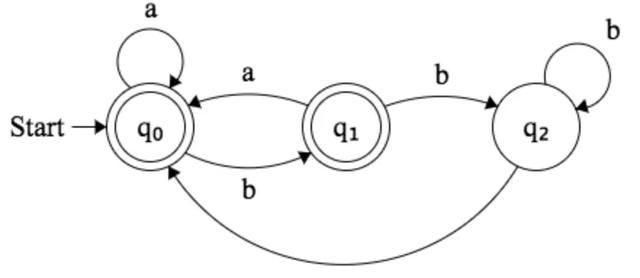
2、DFA法
DFA即deterministic finite automaton有限状态自动机,其特点是可以实现状态的自动转移,可以用于解决字符匹配问题
(1) 核心构成
DFA的核心构成要素是状态和状态的转移
- 定义自动机所具备的N种状态,并定义初始状态
- 定义上一个状态转移至下一个状态的条件
(2) 应用实践
如何用DFA实现词法分析器呢,步骤如下
- 先定义不同的状态 :如操作符状态、数字状态、符号状态等
- 再定义状态转移条件 :如当前状态是初始状态,遇到数字则转移至数字状态,遇到符号则转移至符号状态
- 如果字符读取完成,则整个转移过程结束
(3) 伪代码
let state = 0; // 当前状态, 也是初始状态while ((ch = nextChar()) !== false) { let match = false; // 获取下一个状态, 如果下一个状态不是初始状态, 则说明匹配成功 let nextState = getNextState(ch, state); if (nextState) { match = true; } // 如果匹配成功, 则字符读取序列的下标+1,并转移至下一个状态 if (match) { incrSeq(); flowtoNextState(ch, nextState); } else { // 不匹配则生成token,并转移至初始状态,开始重新匹配 produceToken(); flowtoResetState(); }}复制代码(4) 优点
- 逻辑清晰简单
- 可维护性高,可扩展能力高
- 时间复杂度为O(N),效率高
(5) 一些例子
1) 匹配字符串
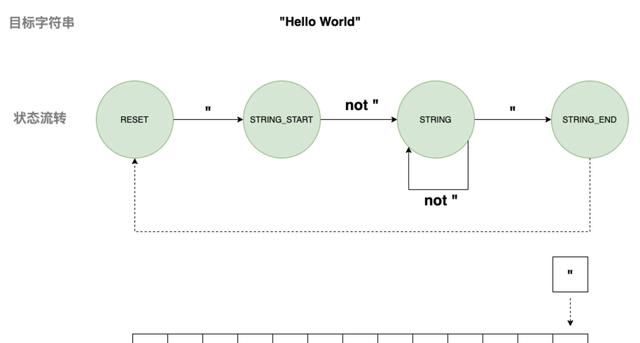
2) 匹配浮点数
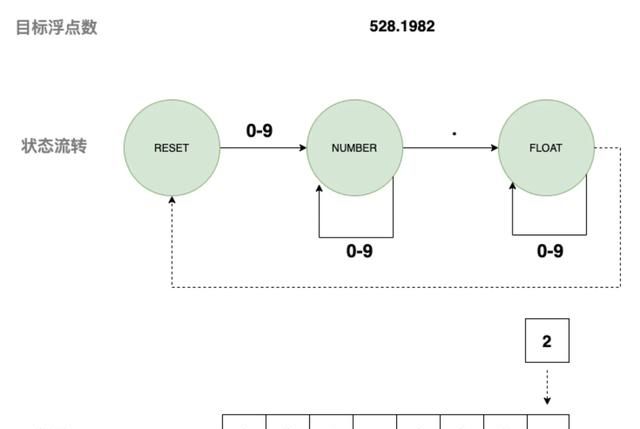
3) 匹配字符
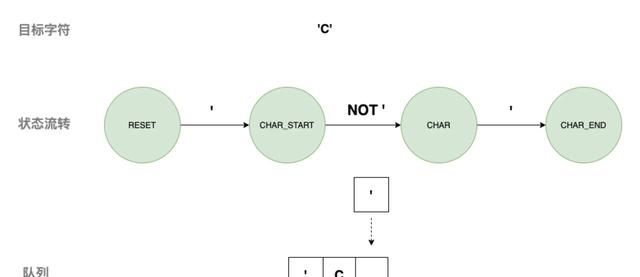
4) 匹配运算符
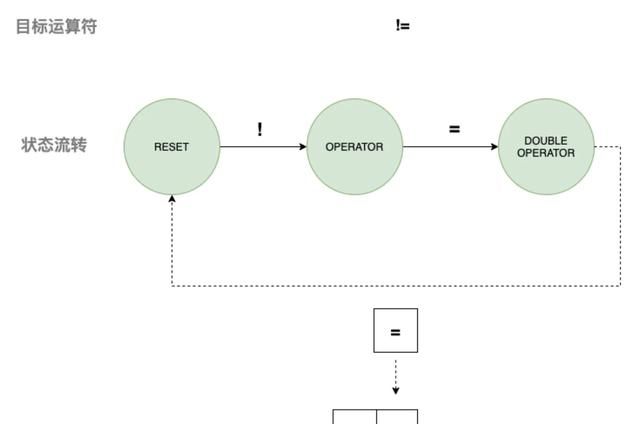
五、词法分析器的实现
词法分析器的详细实现及源码讲解,参见 ***/WGrape/lexer 项目
六、结束语
本文已结束,感谢阅读,点击查看原文