之前发了一篇关于文件处理小实验的文章,不知道大家有没有看呢?那篇文章真的很关键,之前我本以为没有爬取成功的原因是因为我的文件处理部分出现的问题,后来经过两个小测试之后才发现并不是我的文件处理出现了问题,而是提取url的过程中出现了问题。
不过花费一些时间之后,我终于弄懂了!
(我最后所爬取,以及代码全部在文末,大家可以自己去看)
下面,我们就来讲一下如何进行一次完整的爬虫。
在进入正题之前,首先我们需要知道进行一次爬虫,我们需要哪些东西:
- 一台电脑;(最好给自己配一个21存的显示器,笔记本显示器太小,写代码很伤身)电脑里面已经配置好了python的运行环境,我建议大家使用ipython,真的,不吹牛皮,ipython比python自带的ide交互工具好用100倍!了解一些python的基本语法;(不要以为很难,其实我的python也才开始学,自己随便买本关于python书,前8章,一字不漏地全部看完,一气呵成!千万不要拖拉,我当时看零基础入门学python的时候,天连着下了两天暴雨,哪里也去不了,女朋友爱学习,没办法,我也就窝在宿舍,这两天的时间,恰逢卢本伟开挂,蛇哥开挂,电竞圈动荡不堪,而与此相反,我的心却很静,两天看完了8章内容,之后就感觉自己升华(变傻)了·····)
4.一些基本的库,requests;bs4;正则表达式(我下一个学习目标)
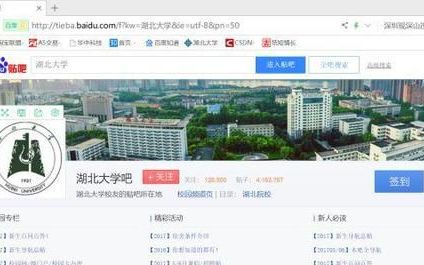
首先我们先打开湖北大学的百度贴吧
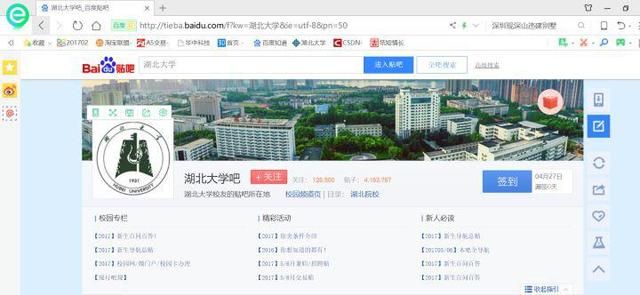
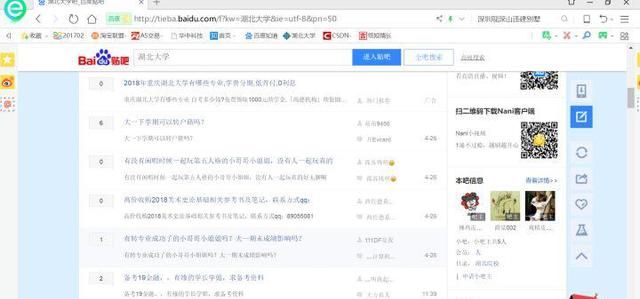
这是一张网页,大家应该都明白,只要是网页,那么就有url,不要感觉url时什么高大上的东西,它其实大概就是,我们平时所说的网址。 那么上面这张图的网址(url)就是:***/f?kw=%E6%B9%96%E5%8C%97%E5%A4%A7%E5%AD%A6&ie=utf-8&pn=50。
湖北大学吧-百度贴吧--湖北大学校友的贴吧所在地
tieba.baidu.com

在这里,我们要知道一点关于网页的知识,大家可以按F12,打开网页的审查元素,就可以看见如下的图:
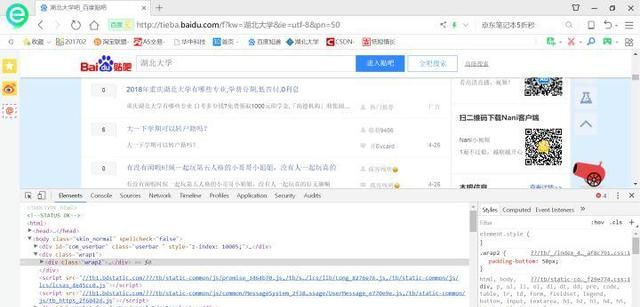
下面的那一块,就是审查元素,用来给开发人员使用的。
我们可以将代码复制在文档里面,帮助我们分析:

也可以使用html.prettify()这个方法将自己的代码转成标准的css和html语言的格式。
很容易分析出来,每个独立的信息都保存在li这个标签中:

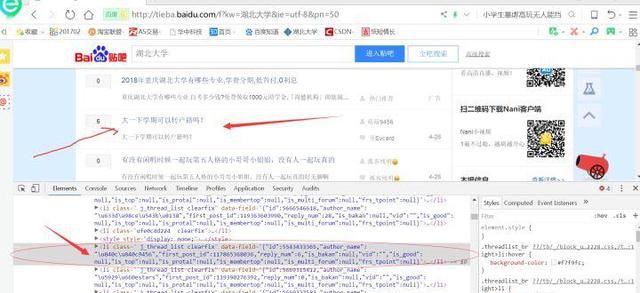
同理分析出,发帖标题和发帖人,回复数量,以及发帖内容,代码如下:
In [1]: import requestsIn [2]: from bs4 import BeaytifulSoupIn [3]: comments=[]In [4]: r=requests.get('***/f?kw=%E6%B9%96%E5%8C%97%E5%A4%A7%E5%AD%A6&ie=utf-8&pn=50') ...: soup=BeautifulSoup(r.content,'lxml') ...: Tags=soup.find_all('li',attrs={"class":" j_thread_list clearfix"}) ...: for li in Tags: ...: comment={} ...: a=li.find('div',attrs={"class":"threadlist_title pull_left j_th_tit "}) ...: comment["title"]=a.text.strip() ...: b=li.find('span',attrs={"class":"frs-author-name-wrap"}) ...: comment["author"]=b.text.strip() ...: c=li.find('div',attrs={"class":"threadlist_abs threadlist_abs_onlyline "}) ...: comment["read"]=c.text.strip() ...: d=li.find('span',attrs={"class":"threadlist_rep_num center_text"}) ...: comment["reply"]=d.text.strip() ...: comments.append(comment) ...: with open(r'C:\Users\13016\Desktop\6.txt','a+',encoding='utf-8') as f: ...: for word in comments: f.write('标题:{} \t发帖人:{} \t发帖内容:{} \t帖子回复量:{} \t\n'.format(word["title"],word["author"],word["read"],word["reply"]))这串代码的含义,我大致捋一下:
- 调用requests库调用bs4库创建一个空列表commentsget到url“制作一碗美味的汤”:soup获取这个网页的每个主体的全部信息,很明显‘li’是每个信息体的标签,将其保存在Tags中循环得到Tags中的每个主体创建一个空字典循环,用find方法获取每个主体中的标题,作者,发帖内容,回复数量,a.text.strip()的意思是,将所获取的单个标签仅保存文字内容,并且用strip()方法去除其中的空格(\n)符号;使用 with as 语句将所爬取的内容保存到本地文档中for in 语句循环获得 coments列表中的每个元素,仔细分析,每个元素均为一个字典结束
大致上,静态网页的爬虫就是这样做的,······码字很累,不太想写了。 大家可以评论火私聊我,来讨论!
最后给大家看一下爬取的结果,应该是这样的:

希望大家能点个赞!